25.10.02 개발일지
[이것이 C#이다 chapter 10, 11, 12]
배열/컬렉션/인덱서, 일반화 프로그래밍과 예외 처리하기
chapter 10
배열

배열을 초기화 하는 방법은 세가지가 있다.
(1)

(2)

(3)

인덱스
인덱스sms 0부터 시작
^연산자 : 컬렉션의 마지막부터 역순으로 인덱스를 지정하는 기능을 갖고 있다.
^1 : 컬렉션의 마지막 요소를 나타내는 인덱스
Length-1 = ^1 = System.Index last
System.Array

<T>는 형식 매개변수라고 하는데, 이들 메소드를 호출할 때는 T자리에 배열의 기반 자료형(int 등)을 인수로 입력하면 컴파일러가 해당 형식에 맞춰 동작하도록 메소드를 컴파일한다.
배열 분할하기
배열 분할은 System.Array의 Array.Copy() 메소드도 가능하지만,
System.Range 방식을 사용하는게 더 편하다.

마지막 인덱스는 배열 분할 결과에서 제외된다.

시작 인덱스를 생략하면 첫번째 요소 위치를 시작 인덱스로 간주하고,
마지막 인데스를 생략하면 마지막 요소 위치를 마지막 인덱스로 간주하고,
둘 다 생략하면 배열 전체가 된다.

System.Range 객체를 생성할 때 System.Index 객체를 이용할 수도 있다.
2차원 배열

int[2, 3] : 기반 형식이 int이며 길이는 3인 1차원 배열을 원소로 2개 갖고 있는 2차원 배열(뒤에서 부터 읽기)
2차원 배열을 foreach 문에 넣고 각 요소의 데이터를 출력하면 배열의 요소값을 1차원적으로, 순서대로 가져온다.
numbers는 사실상 메모리상에 [ 1, 2, 3, 4, 5, 6 ] 형태로 저장되어 있다.
따라서 foreach는 이 내부 순서를 따라 순회한다(행 우선 순서)
만약 행/열 정보까지 포함해서 출력하고 싶다면 for중첩문을 써야 한다.
가변 배열
배열을 요소로 갖는 배열

2차원 배열과는 다르다.
선언 방법도 [ , ] <-> [ ][ ]으로 다르고, 가변 배열의 요소로 입력되는 배열은 그 길이가 모두 같을 필요가 없다.
위에 jagged라는 가변배열은 0번 요소에는 길이가 5인 배열, 1번 요소에는 길이가 3인 배열, 그리고 2번 요소에는 길이가 2인 배열을 할당했다.
가변배열의 요소는 배열이다.
컬렉션
컬렉션 : 같은 성격을 띤 데이터의 모음을 담는 자료구조
배열도 .NET이 제공하는 다양한 컬렉션 자료구조의 일부이다.

1) ArrayList
배열과 가장 닮은 컬렉션
하지만 배열과 달리 컬렉션을 생성할 때 용량을 미리 지정할 필요 없이 필요에 따라 자동으로 그 용량이 늘어나거나 줄어드는 큰 장점이 있다.

Add( ) : 컬렉션의 마지막에 있는 요소 뒤에 새 요소를 추가
RemoveAt( ) : 특정 인덱스에 있는 요소를 제거
Insert( ) : 원하는 위치에 새 요소를 삽입
2) Queue
대기열, 기다리는 줄 이라는 뜻
데이터나 작업을 차례대로 입력해뒀다가 입려된 순서대로 하나씩 꺼내 처리하기 위해 사용된다.
입력은 오직 뒤에서, 출력은 앞에서만 이루어진다.
데이터 입력은 오로지 뒤에서 Enqueue( ) 메소드를 이용해서 한다.
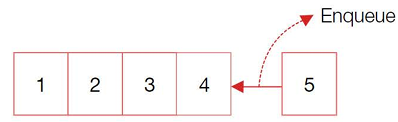
반대로 데이터를 꺼낼 때는 Dequeue( ) 메소드를 사용한다.
Dequeue( ) 를 실행하면 데이터를 자료구조에서 실제로 꺼내게 된다.
-> 가장 앞에 있던 항목이 출력되고 나며 그 뒤에 있던 항목이 가장 앞으로 옮겨진다.
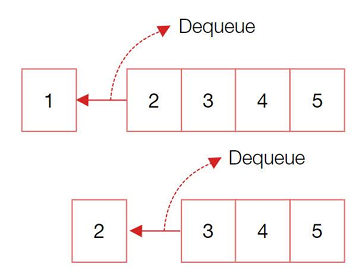
3) Stack
Stack은 Queue와 반대로 먼저 들어온 데이터가 나중에 나가고, 나중에 들어온 데이터는 먼저 나가는 구조의 컬렉션이다.

Stack에 데이터를 넣을 때는 Push( ) 메소드를 이용하고, 데이터를 꺼낼 때는 Pop( ) 메소드를 이용한다.
4) Hashtable
키(Key)와 값(Value)의 쌍으로 이루어진 데이터를 다룰 때 사용한다.
탐색 속도가 빠르고 사용하기도 편하다.
배열과 비슷하지만 배열이 데이터를 저장할 요소의 위치로 인덱스를 사용하는 반면에, Hashtable 컬렉션은 키 데이터를 그대로 사용한다.
키는 int, float, 문자열, 클래스 등 모두 가능하다.
컬렉션을 초기화 하는 방법
ArrayList, Queue, Stack 은 배열의 도움을 받아 간단하게 초기화를 수행할 수 있다.

ArrayList는 배열의 도움없이 직접 컬렉션 초기자를 이용해서 초기화할 수 있다.

Stack과 Queue는 컬렉션 초기자를 이용할 수 없다.
Hashtable을 초기화할 때는 딕셔너리 초기자를 이용한다.

인덱서
인덱스를 이용해서 객체 내의 데이터에 접근하게 해주는 프로퍼티

프로퍼티는 객체 내의 데이터에 접근할 수 있도록 하는 통로이다.
인덱서도 프로퍼티처럼 객체 내의 데이터에 접근할 수 있도록 하는 통로이다.
foreach가 가능한 객체 만들기
foreach문은 배열이나 리스트 같은 컬렉션에서만 사용할 수 있다.
배열을 구현한 클래스에서는 foreach문을 사용할 수 없다.
-> 그 이유는 foreach 문은 IEnumerable을 상속하는 형식만 지원한다.
-> 이말은 클래스도 IEnumerable을 상속하기만 하면 foreach문을 사용할 수 있다는 것이다.
-> yield 문을 이용하면 IEnumerable을 상속하는 클래스를 따로 구현하지 않아도 컴파일러가 자동으로 해당 인터페이스를 구현한 클래스를 생성해준다.


chapter 11
일반화 프로그래밍
일반화 : 특수한 개념으로부터 공통된 개념을 찾아 묶는 것
일반화 프로그래밍의 일반화하는 대상은 데이터 형식이다.
일반화 메소드
일반화 메소드는 데이터 형식을 일반화한 메소드다.
일반화할 형식이 들어갈 자리에 구체적인 형식의 이름 대신 형식 매개변수(T)가 들어간다.

이렇게 선언하면

형식 매개변수 T 자리에 형식 이름만 바꿔주면 여러개의 형식을 지원할 수 있다.
일반화 클래스

기능은 같지만 내부적으로 사용하는 데이터 형식이 다르면 클래스를 분리해서 구현했지만,
일반화 클래스로 구현하면 형식 매개변수 T는 객체를 생성할 때 입력받은 형식으로 치환되어 컴파일된다.
형식 매개변수 제약시키기
형식 매개변수 T는 모든 데이터 형식을 대신할 수 있다.
하지만 종종 특정 조건을 갖춘 형식에만 대응하는 형식 매개변수가 필요할 때도 있다.
이때 형식 매개변수의 조건에 제약을 줄 수 있다.


일반화 컬렉션
컬렉션 클래스들을 object 형식으로 선언하면 어떤 형식이든 형식 변환이 가능하다.
그러나 컬렉션의 요소에 접근할 때마다 형식변환이 일어나기 때문에 성능 문제를 안고 있다.
-> 일반화 컬렉션을 사용하면 컴파일할 때 컬렉션에서 사용할 형식이 결정되고, 쓸데없는 형식 변환을 일으키지 않는다.

이것들은 컬렉션 ArrayList, Queue, Stack, Hashtable의 일반화 버전이다.
1) List<T>
ArrayList와 같은 기능을 하며 사용법 역시 동일하다.
차이점은 List<T> 클래스는 인스턴스를 만들 때 형식 매개변수가 필요하다는 것과,
한 컬렉션에 아무 형식의 객체나 마구 집어넣을 수 있었떤 ArrayList와 달리 List<T>는 형식 매개변수에 입력한 형식 외에는 입력을 허용하지 않는다.
2) Queue<T>
형식 매개변수를 요구한다는 점만 다를 뿐, 비일반화 클래스인 Queue와 같은 기능을 하며 사용법도 동일하다.
3) Stack<T>
형식 매개변수를 요구한다는 점만 다를 뿐, 비일반화 클래스인 Stack과 같은 기능을 하며 사용법도 동일하다.
4) Dictionary<TKey, TValue>
형식 매개변수를 2개 요구한다.
TKey는 Key, TValue는 Value를 위한 형식이다.
foreach를 사용할 수 있는 일반화 클래스
출처 입력
일반화 클래스도 IEnumerable 인터페이스를 상속하면 일단은 foreach를 통해 순회할 수 있지만,
요소를 순회할 때마다 형식 변환을 수행하는 오버로드가 발생한다는 문제가 있다.
-> IEnumerable의 일반화 버전인 IEnumberable<T> 인터페이스를 상속하면 형식 변환으로 인한 성능 저하가 없으면서도 foreach 순회가 가능한 클래스를 작성할 수 있다.
chapter 12
예외
예외 : 프로그래머가 생각한 시나리오에서 벗어나는 사건
예외 처리 : 예외가 프로그램의 오류나 다운으로 이어지지 않도록 적절하게 처리하는 것
예외 처리는 실제 일을 하는 코드와 문제를 처리하는 코드를 깔끔하게 분리시킴으로써 코드를 간결하게 만들어준다.
또, 예외 객체의 StackTrace 프로퍼티를 통해 문제가 발생한 부분의 소스 코드 위치를 알려주기 때문에 디버깅이 아주 용이하다.
try~catch로 예외 받기

catch 절은 try 블록에서 던질 예외 객체와 형식이 일치해야 한다.
System.Exception 클래스
System.Exception 클래스는 모든 예외의 조상이다.
-> C#에서 모든 예외 클래스는 반드시 이 클래스로부터 상속받아야 한다.
-> 상속 관계로 인해 모든 예외 클래스들은 System.Exception 형식으로 간주할 수 있고 System.Exception 형식의 예외를 받는 catch 절 하나면 모든 예외를 다 받아낼 수 있다.
-> 프로그래머가 발생할 것으로 계산한 예외 말고도 다른 예외까지 받아낼 수 있어 버그를 만들 수 있다.
예외 던지기
try~catch 문으로 예외를 받는다는 것은 어디선가 예외를 던진다는 이야기다.
throw문으로 예외를 던질 수 있다.

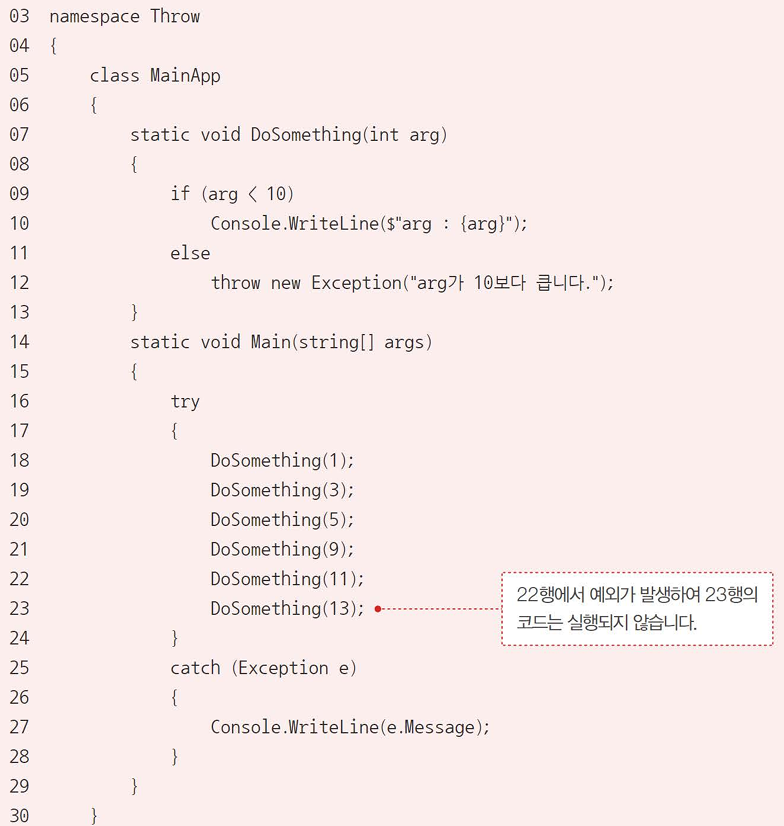


try~catch와 finally
예외 때문에 try 블록의 자원 해제 같은 중요한 코드가 미처 실행하지 못한다면 이는 곧 버그를 만드는 원인이 된다.
예를 들어 try 블록 끝에 데이터베이스의 커넥션을 닫는 코드가 있었는데 갑자기 발생한 예외 때문에 이것을 실행하지 못한다면 문제가 될 수 있다.
그렇다고 자원을 해제하는 코드를 모든 catch 절에 배치하는 것도 우스운 일이다.
이럴때 finally 절을 사용해 뒷정리 코드를 넣어주면 된다.

try절이 실행된다면 finally 절은 어떤 경우라도 실행된다.
예외가 일어나지 않고 정상적으로 return 하더라도, 예외가 일어나더라도 finally 절은 실행된다.
finally 절에서도 예외가 일어날 수 있다.
-> 이 안에서 다시 한번 try~catch 절을 사용하는 것도 방법이다.
사용자 정의 예외 클래스 만들기
C#에서 사용하는 모든 예외 객체는 System.Exception 클래스로부터 파생되어야 한다.
-> Exception 클래스를 상속하기만 하면 새로운 예외 클래스를 만들 수 있다.

.NET이 100여가지 넘는 예외 형식을 제공하기 때문에 사실 사용자 정의 예외는 그렇게 자주 필요하진 않다.
하지만 특별한 데이터를 담아서 예외 처리 루틴에 추가 정보를 제공하고 싶거나 예외 상황을 더 잘 설명하고 싶을 때는 사용자 정의 예외 클래스를 만들어서 사용하면 좋다.
예외 필터
catch 절이 받아들일 예외 객체에 제약 사항을 명시해서 해당 조건을 만족하는 예외객체에 대해서만 예외처리 코드를 실행할 수 있도록 하는 예외 필터가 도입됐다.
catch 절 뒤에 when 키워드를 이용해서 제약 조건을 기술하면 된다.

'10월 개발일지' 카테고리의 다른 글
| 25.10.14 개발일지(C# 개인 프로젝트 게임 만들기) (0) | 2025.11.16 |
|---|---|
| 25.10.13 개발일지(이것이 C#이다 chapter 21, 22) (0) | 2025.11.16 |
| 25.10.06 개발일지(이것이 C#이다 chapter 20) (0) | 2025.11.16 |
| 25.10.05 개발일지(이것이 C#이다 chapter 13, 19) (0) | 2025.11.16 |
| 25.10.01 개발일지(이것이 C#이다 chapter 8, 9) (0) | 2025.11.16 |